KWCounts generates keyword counts from PGR passport database
fields(columns).
Details
This function computes the keyword counts from PGR passport database
fields(columns) specified in the fields argument. The first field is
considered as the primary key or identifier and is not used for counting the
keywords. Any strings given in the excep argument are ignored for
generating the counts.
The keyword counts can give a rough indication of the completeness of the data in the database fields being used for identification of probable duplicates.
Note
For large number of exceptions and/or large data.frame computation of keyword counts may take some time.
Examples
# Load PGR passport database
GN <- GN1000
# Specify database fields to use as a vector
GNfields <- c("NationalID", "CollNo", "DonorID", "OtherID1", "OtherID2")
# Specify the exceptions as a vector
exep <- c("A", "B", "BIG", "BOLD", "BUNCH", "C", "COMPANY", "CULTURE",
"DARK", "E", "EARLY", "EC", "ERECT", "EXOTIC", "FLESH", "GROUNDNUT",
"GUTHUKAI", "IMPROVED", "K", "KUTHUKADAL", "KUTHUKAI", "LARGE",
"LIGHT", "LOCAL", "OF", "OVERO", "P", "PEANUT", "PURPLE", "R",
"RED", "RUNNER", "S1", "SAM", "SMALL", "SPANISH", "TAN", "TYPE",
"U", "VALENCIA", "VIRGINIA", "WHITE")
# Compute the keyword counts
GNKWCouts <- KWCounts(GN, GNfields, exep)
# Plot the keyword counts
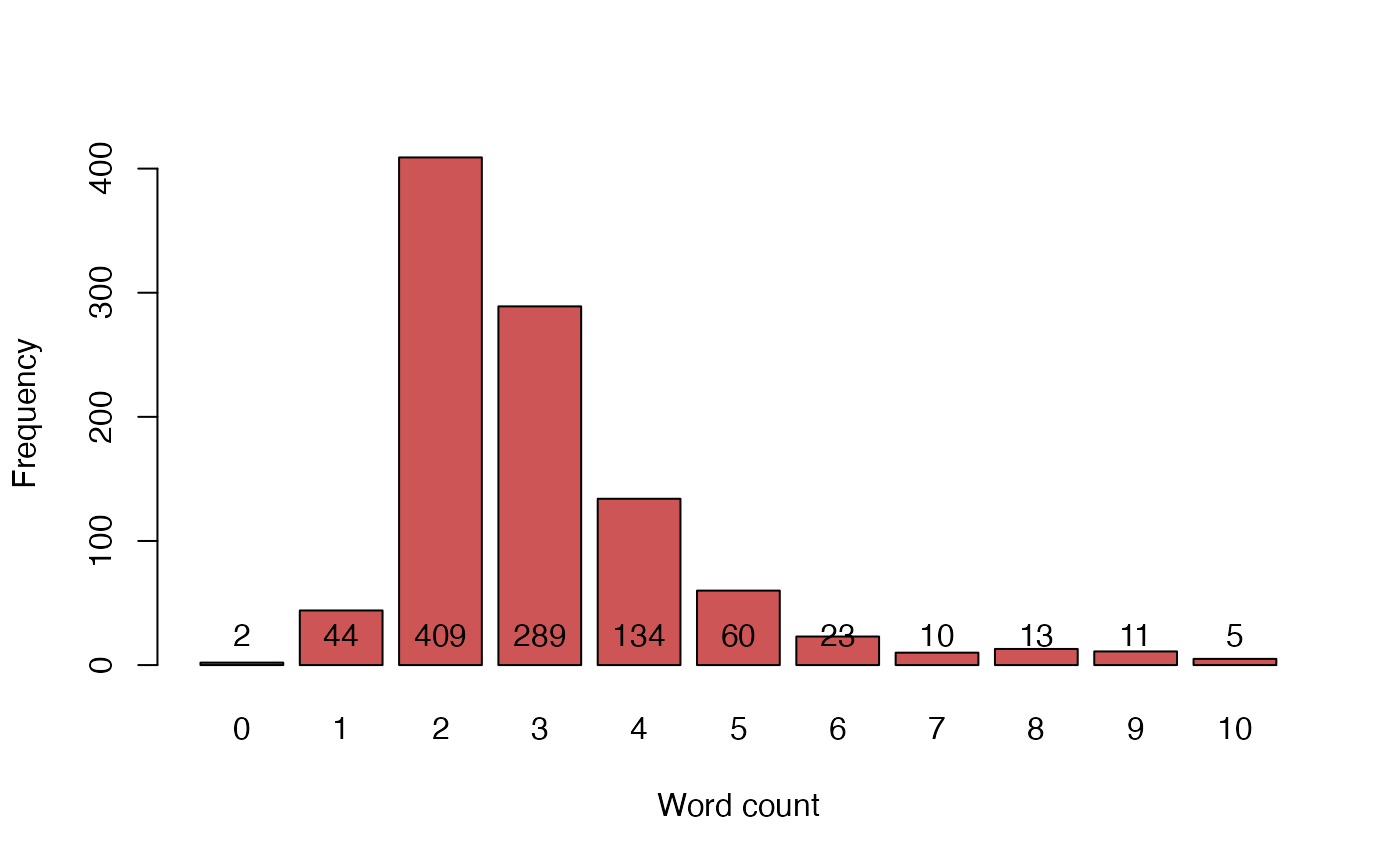
bp <- barplot(table(GNKWCouts$COUNT),
xlab = "Word count", ylab = "Frequency", col = "#CD5555")
text(bp, 0, table(GNKWCouts$COUNT),cex=1,pos=3)