Analysis of Augmented Randomised Complete Block Design for Multiple Traits/Characters
Source:R/augmentedRCBD.bulk.R
augmentedRCBD.bulk.RdaugmentedRCBD.bulk is a wrapper around the functions
augmentedRCBD, describe.augmentedRCBD,
freqdist.augmentedRCBD and gva.augmentedRCBD. It will carry out
these analyses for multiple traits/characters from the input data as a data
frame object.
Usage
augmentedRCBD.bulk(
data,
block,
treatment,
traits,
checks = NULL,
check.inference = c("overall", "traitwise"),
alpha = 0.05,
describe = TRUE,
freqdist = TRUE,
gva = TRUE,
k = 2.063,
check.col = "red",
console = TRUE
)Arguments
- data
The data as a data frame object. The data frame should possess columns specifying the block, treatment and multiple traits/characters.
- block
Name of column specifying the blocks in the design as a character string.
- treatment
Name of column specifying the treatments as a character string.
- traits
Name of columns specifying the multiple traits/characters as a character vector.
- checks
Character vector of the checks present in
treatmentlevels. It can also be a named list with the character vector of checks for each trait intraitscolumn. The list names should be same as trait names. If not specified, checks are inferred from the data on the basis of number of replications of treatments/genotypes.- check.inference
The method for inference of checks if
checksis not specified. Either"overall"to infer checks on the basis of all the trait data or"traitwise"to infer checks on the basis of each trait separately.- alpha
Type I error probability (Significance level) to be used for multiple comparisons.
- describe
If
TRUE, descriptive statistics will be computed. Default isTRUE.- freqdist
If
TRUE, frequency distributions be plotted. Default isTRUE.- gva
If
TRUE, genetic variability analysis will be done. Default isTRUE.- k
The standardized selection differential or selection intensity required for computation of Genetic advance. Default is 2.063 for 5% selection proportion (see Details in
gva.augmentedRCBD). Ignored ifgva = FALSE.- check.col
The colour(s) to be used to highlight check values in the plot as a character vector. Must be valid colour values in R (named colours, hexadecimal representation, index of colours [
1:8] in default Rpalette()etc.).- console
If
TRUE, output will be printed to console. Default isTRUE.
Value
A list of class augmentedRCBD.bulk containing the following
components:
DetailsDetails of the augmented design used and the traits/characters.
ANOVA, Treatment AdjustedA data frame of mean sum of squares, p value and stastical significance of the specified traits from treatment adjusted ANOVA.
ANOVA, Block AdjustedA data frame of mean sum of squares, p value and stastical significance of the specified traits from block adjusted ANOVA
MeansA data frame of the adjusted means of the treatments for the specified traits.
Check statisticsA list of data frames with check statistics such as number of replications, standard error, minimum and maximum value
alphaType I error probability (Significance level) used.
Std. ErrorsA data frame of standard error of difference between various combinations for the specified traits.
CDA data frame of critical difference (at the specified alpha) between various combinations for the specified traits.
Overall adjusted meanA data frame of the overall adjusted mean for the specified traits.
CVA data frame of the coefficient of variance for the specified traits.
Descriptive statisticsA data frame of descriptive statistics for the specified traits.
Frequency distributionA list of ggplot2 plot grobs of the frequency distribution plots.
kThe standardized selection differential or selection intensity used for computaton of Genetic advance.
Genetic variability analysisA data frame of genetic variability statistics for the specified traits.
GVA plotsA list of three ggplot2 objects with the plots for (a) Phenotypic and Genotypic CV, (b) Broad sense heritability and (c) Genetic advance over mean
warningsA list of warning messages (if any) captured during model fitting, frequency distribution plotting and genetic variability analysis.
Note
In this case treatment comparisons/grouping by least significant
difference or Tukey's honest significant difference method is not computed.
Also the output object size is reduced using the simplify = TRUE
argument in the augmentedRCBD function.
Examples
# Example data
blk <- c(rep(1,7),rep(2,6),rep(3,7))
trt <- c(1, 2, 3, 4, 7, 11, 12, 1, 2, 3, 4, 5, 9, 1, 2, 3, 4, 8, 6, 10)
y1 <- c(92, 79, 87, 81, 96, 89, 82, 79, 81, 81, 91, 79, 78, 83, 77, 78, 78,
70, 75, 74)
y2 <- c(258, 224, 238, 278, 347, 300, 289, 260, 220, 237, 227, 281, 311, 250,
240, 268, 287, 226, 395, 450)
dataf <- data.frame(blk, trt, y1, y2)
bout <- augmentedRCBD.bulk(data = dataf, block = "blk",
treatment = "trt", traits = c("y1", "y2"),
checks = NULL, alpha = 0.05, describe = TRUE,
freqdist = TRUE, gva = TRUE,
check.col = c("brown", "darkcyan",
"forestgreen", "purple"),
console = TRUE)
#>
#> ANOVA for y1 computed (1/2)
#>
#> ANOVA for y2 computed (2/2)
#>
#> Augmented Design Details
#> ========================
#> Trait Number of blocks Number of treatments Number of check treatments
#> 1 y1 3 12 4
#> 2 y2 3 12 4
#> Number of test treatments Check treatments
#> 1 8 1, 2, 3, 4
#> 2 8 1, 2, 3, 4
#>
#>
#> ANOVA, Treatment Adjusted
#> =========================
#> Mean.Sq
#> Source Df y1 Df y2
#> Block (ignoring Treatments) 2 180.04 * 2 3509.67 **
#> Treatment (eliminating Blocks) 11 25.92 ⁿˢ 11 5360.49 **
#> Treatment: Check 3 17.64 ⁿˢ 3 716.75 ⁿˢ
#> Treatment: Test and Test vs. Check 8 29.02 ⁿˢ 8 7101.89 **
#> Residuals 6 26.97 6 286.25
#> ⁿˢ P > 0.05; * P <= 0.05; ** P <= 0.01
#>
#> ANOVA, Block Adjusted
#> =====================
#> Mean.Sq
#> Source Df y1 Df y2
#> Treatment (ignoring Blocks) 11 52.33 ⁿˢ 11 5882.50 **
#> Treatment: Check 3 17.64 ⁿˢ 3 716.75 ⁿˢ
#> Treatment: Test 7 72.27 ⁿˢ 7 4980.41 **
#> Treatment: Test vs. Check 1 16.87 ⁿˢ 1 27694.41 **
#> Block (eliminating Treatments) 2 34.75 ⁿˢ 2 638.58 ⁿˢ
#> Residuals 6 26.97 6 286.25
#> ⁿˢ P > 0.05; * P <= 0.05; ** P <= 0.01
#>
#> Coefficient of Variation
#> ========================
#> Trait CV
#> y1 6.37
#> y2 6.06
#>
#>
#> Overall Adjusted Mean
#> =====================
#> Trait Overall.adjusted.mean
#> y1 81.06
#> y2 298.48
#>
#>
#> Standard Errors
#> ===============
#> Comparison y1 y2
#> A Test Treatment and a Control Treatment 6.70 21.84
#> Control Treatment Means 4.24 13.81
#> Two Test Treatments (Different Blocks) 8.21 26.75
#> Two Test Treatments (Same Block) 7.34 23.93
#>
#>
#> Critical Difference
#> ===================
#> alpha = 0.05
#> Comparison y1 y2
#> A Test Treatment and a Control Treatment 16.41 53.45
#> Control Treatment Means 10.38 33.80
#> Two Test Treatments (Different Blocks) 20.09 65.46
#> Two Test Treatments (Same Block) 17.97 58.55
#>
#>
#> Descriptive Statistics
#> ======================
#> Trait Count Mean Std.Error Std.Deviation Min Max Skewness Skewness_sig
#> y1 12 81.06 1.55 5.36 73.25 93.50 0.93 ⁿˢ
#> y2 12 298.48 18.92 65.55 213.67 437.67 0.74 ⁿˢ
#> Kurtosis Kurtosis_sig
#> 3.52 ⁿˢ
#> 2.79 ⁿˢ
#> ⁿˢ P > 0.05; * P <= 0.05; ** P <= 0.01
#>
#>
#> Genetic Variability Analysis
#> ============================
#> k = 2.063
#> Trait Mean PV GV EV GCV GCV.category PCV PCV.category ECV
#> y1 † 81.06 72.27 45.30 26.97 8.30 Low 10.49 Medium 6.41
#> y2 298.48 4980.41 4694.16 286.25 22.95 High 23.64 High 5.67
#> hBS hBS.category GA GAM GAM.category
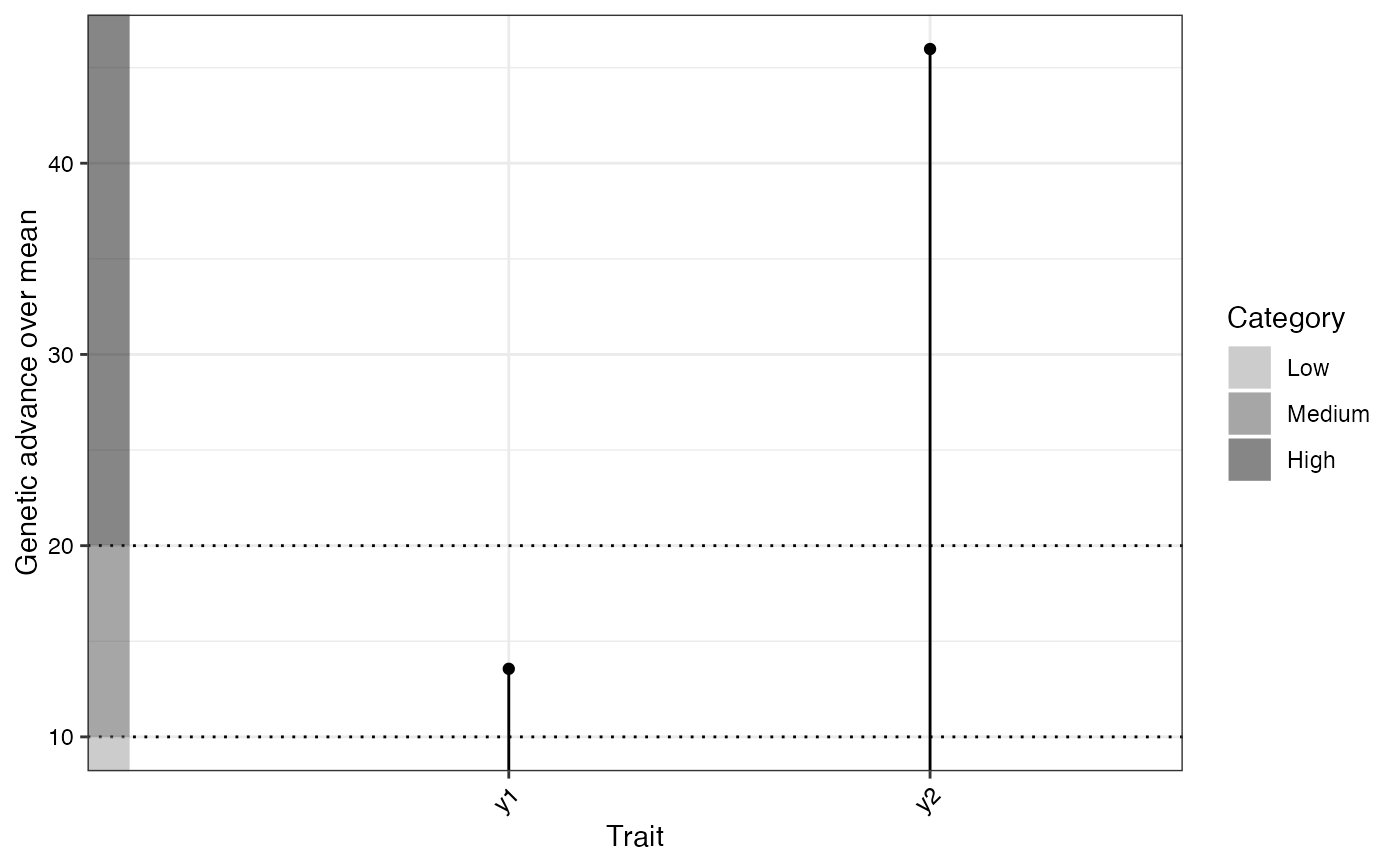
#> 62.68 High 10.99 13.56 Medium
#> 94.25 High 137.22 45.97 High
#>
#> Warning:
#> † P-value for "Treatment: Test" is > 0.05. Genetic variability analysis may not be appropriate for this trait.
#> Warning:
#> ‡ Negative GV detected.
#> GCV, GCV category, hBS, hBS category,GA, GAM and
#> GAM category could not be computed.
#>
#>
#> Warning Messages
#> ================
#>
#>
#> [Frequency Distribution]
#> <y1>
#> Removed 2 rows containing missing values or values outside the scale range
#> (`geom_bar()`).
#>
#> <y2>
#> Removed 2 rows containing missing values or values outside the scale range
#> (`geom_bar()`).
#>
#>
#>
#> [GVA]
#> <y1>
#> P-value for "Treatment: Test" is > 0.05. Genetic variability analysis may not be appropriate for this trait.
#>
#>
#> Treatment Means
#> ===============
#> Treatment Block y1 y2
#> 1 84.67 256.00
#> 10 3 77.25 437.67
#> 11 1 86.50 299.42
#> 12 1 79.50 288.42
#> 2 79.00 228.00
#> 3 82.00 247.67
#> 4 83.33 264.00
#> 5 2 78.25 293.92
#> 6 3 78.25 382.67
#> 7 1 93.50 346.42
#> 8 3 73.25 213.67
#> 9 2 77.25 323.92
# Frequency distribution plots
lapply(bout$`Frequency distribution`, plot)
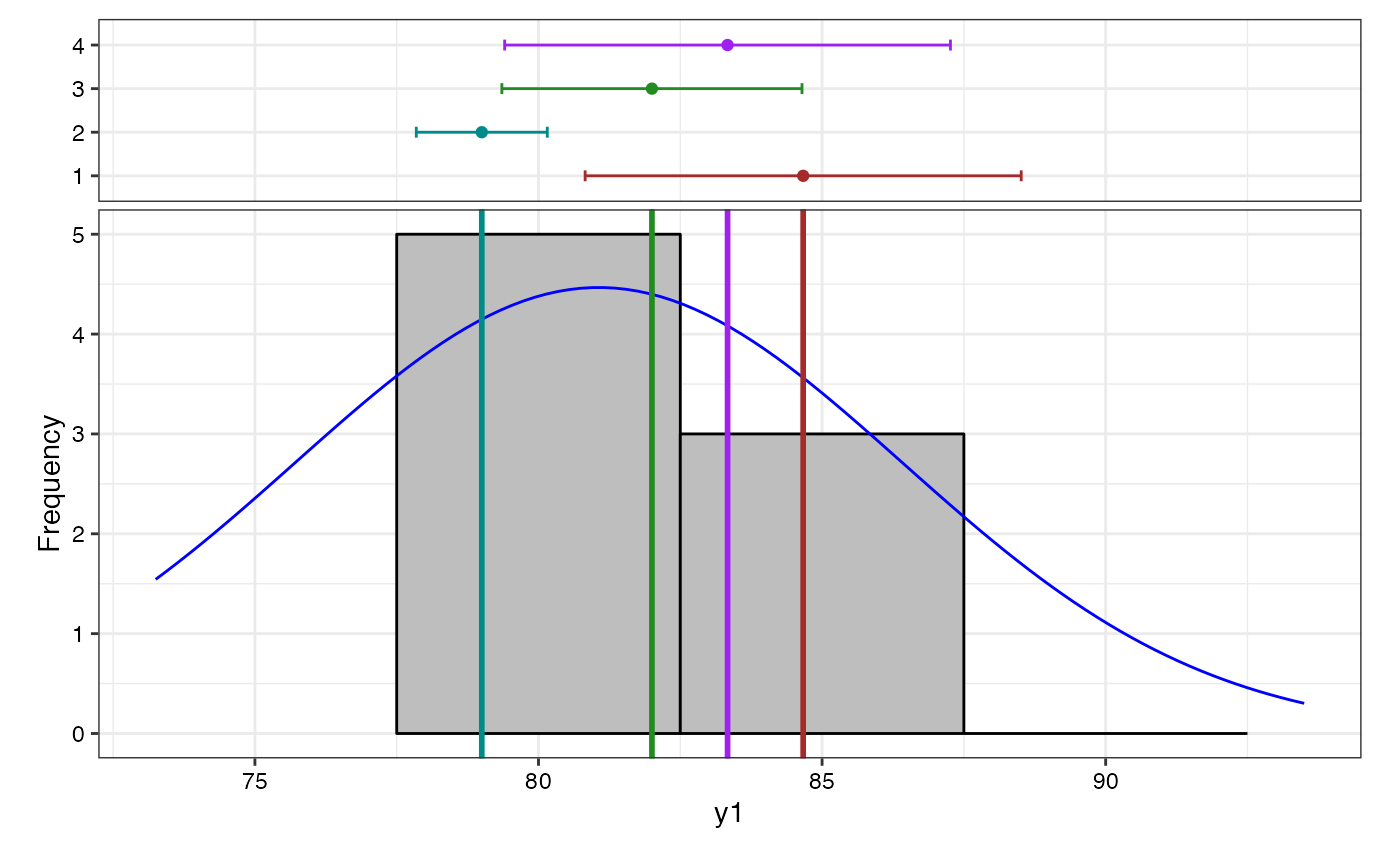
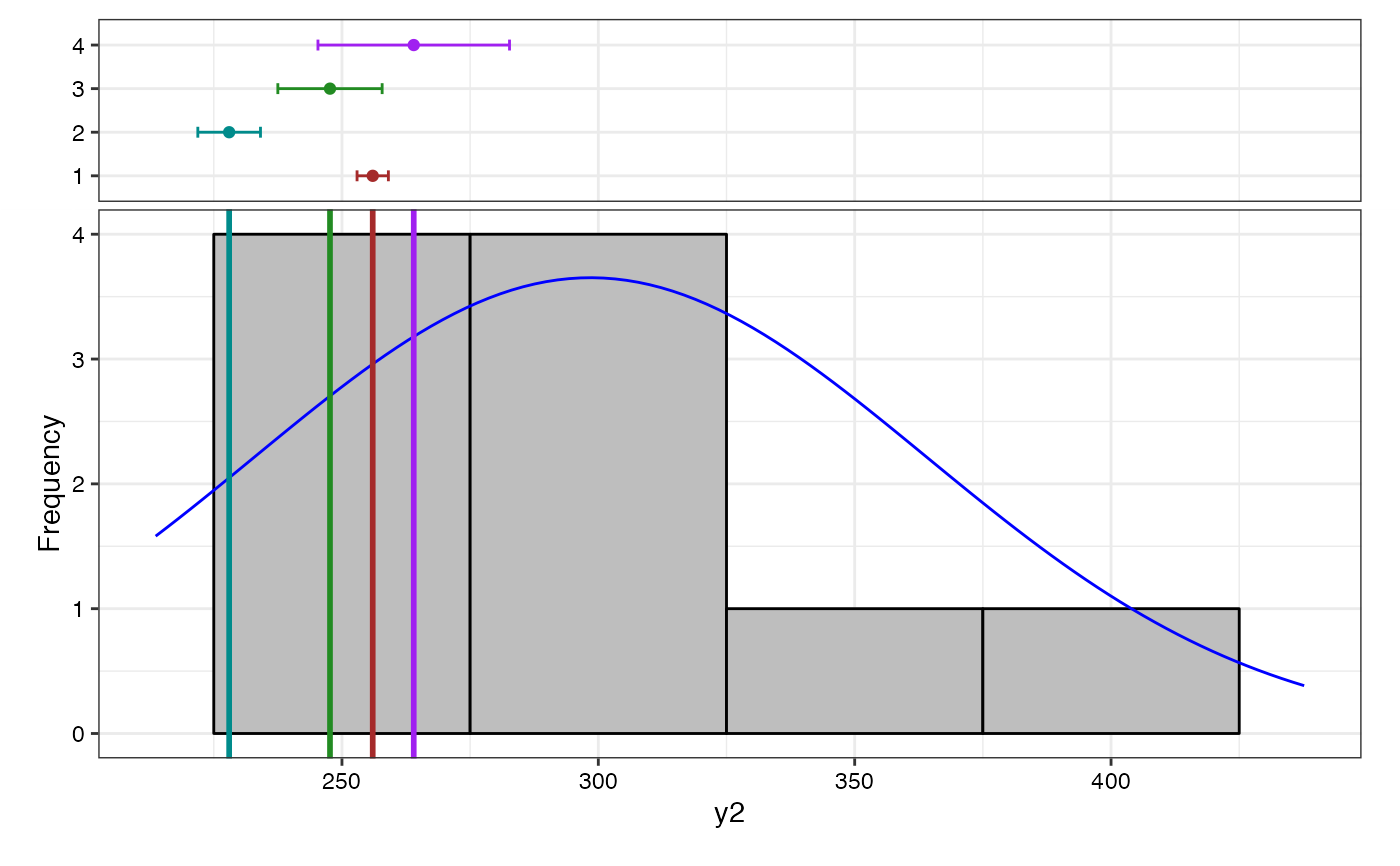 #> $y1
#> NULL
#>
#> $y2
#> NULL
#>
# GVA plots
bout$`GVA plots`
#> $`Phenotypic and Genotypic CV`
#> $y1
#> NULL
#>
#> $y2
#> NULL
#>
# GVA plots
bout$`GVA plots`
#> $`Phenotypic and Genotypic CV`
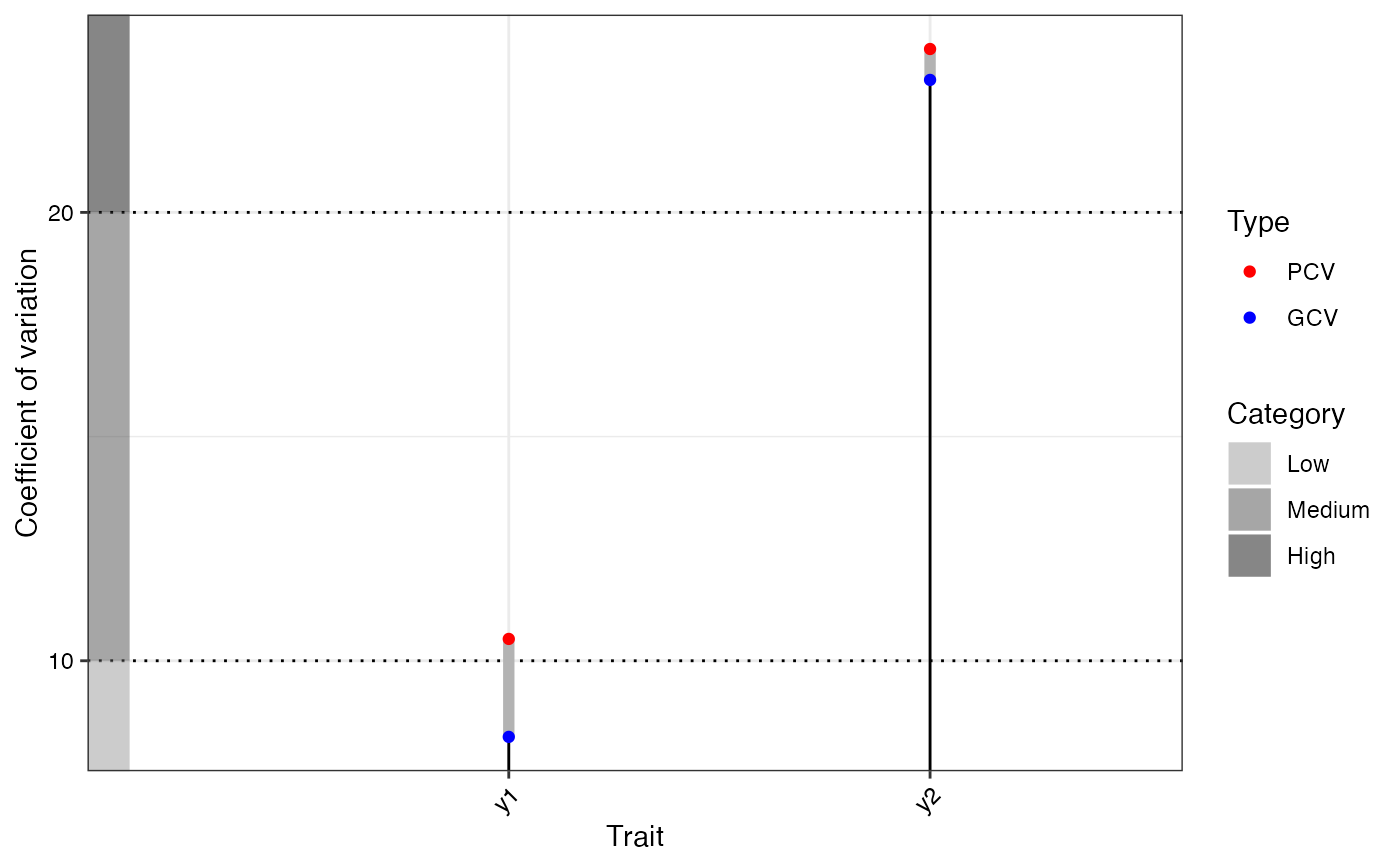 #>
#> $`Broad sense heritability`
#>
#> $`Broad sense heritability`
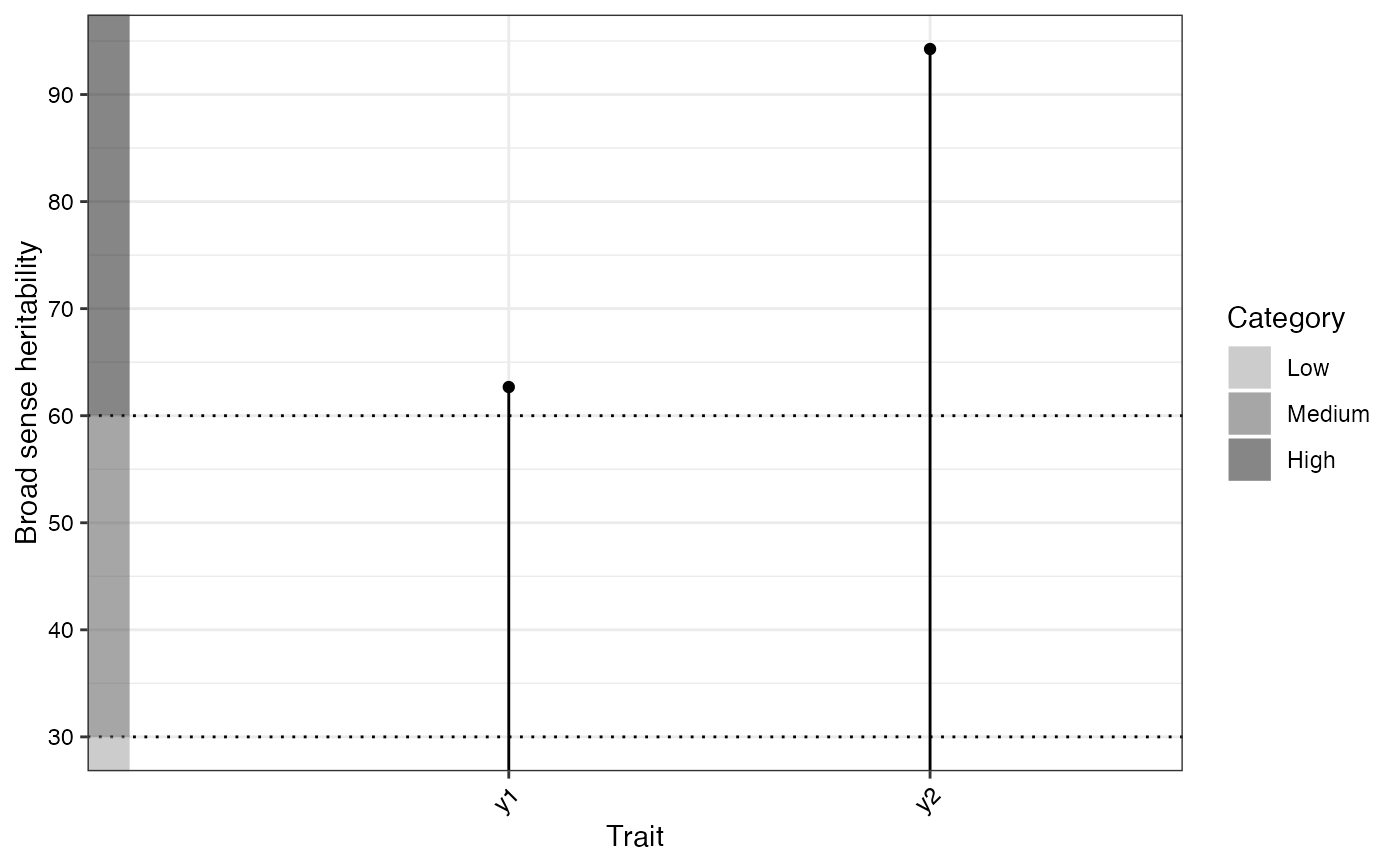 #>
#> $`Genetic advance over mean`
#>
#> $`Genetic advance over mean`
 #>
#>